Kunstmatige intelligentie
Misschien wel de belangrijkste ontwikkeling in kunstmatige intelligentie is het vermogen van computers om beelden te interpreteren, iets dat gebruikt wordt bij het sorteren en annoteren van vakantiekiekjes, maar ook bij het inschatten van verkeerssituaties bij zelfrijdende auto’s. In vrijwel alle gevallen wordt in dit soort toepassingen gebruik gemaakt van Deep Learning, een zogenaamd kunstmatig neuraal netwerk, dat getraind wordt door vaak miljoenen en miljoenen voorbeelden.
In gevallen waarbij het aantal voorbeelden niet zo groot is (zoals in het MODOMA project) wordt vaak gebruik gemaakt van een netwerk dat op een algemene database van voorbeelden is getraind, en alleen nog maar een klein stukje hoeft bij te leren over het onderhavige probleem.
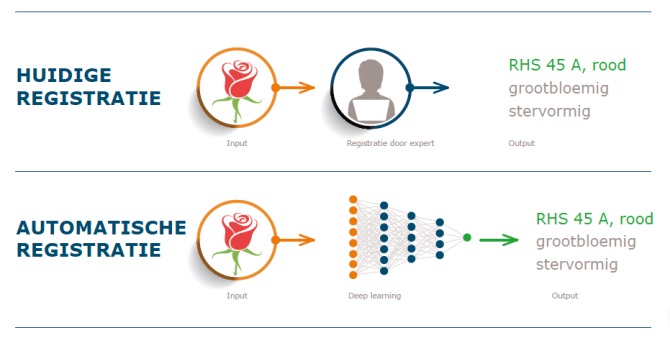
Het project
Bij de productregistratie en het kwekersrechtonderzoek van siergewassen spelen morfologische beschrijvingen van bloemen en planten een belangrijke rol. Deze beschrijvingen worden nu nog handmatig verkregen, in een proces dat een behoorlijke hoeveelheid expertise vereist. Het (gedeeltelijk) automatiseren van dit proces maakt het overal mogelijk “officiële” kenmerken te verkrijgen, iets dat niet alleen voor Naktuinbouw en Floricode, maar ook voor kwekers en veredelaars commercieel interessant is. Het TKI project Modoma (2021-2023) onderzoekt of technieken uit de kunstmatige intelligentie hierbij nuttig kunnen zijn. Door gebruik te maken van moderne AI technieken kunnen modellen getraind worden die, op basis van foto’s van bloemen of planten, een voorspelling doen voor de belangrijke morfologische kenmerken.
Het project kent in principe drie doelen: a) een inventarisatie van de mogelijkheden van AI in deze specifieke context; b) het onderzoeken van mogelijkheden beelden te optimaliseren met automatische interpretatie in het achterhoofd; en c) de implementatie van een prototype. Voor wat betreft a) is in 2022 begonnen met de analyse van de databases van de partners Floricode en Naktuinbouw. Alle kenmerken in de databases zijn geëvalueerd en geprioriteerd, met als resultaat een set van kwalitatieve kenmerken (zoals bloemvorm, bloeiwijze, …), en het kenmerk bloemkleur. Voor dat laatste wordt niet alleen Machine Learning toegepast, maar wordt ook een alternatieve analyse, gebaseerd op klassieke beeldverwerking – dit geeft ons een basis ter vergelijking. De resultaten laten zien dat de kwalitatieve kenmerken allemaal in meer of mindere mate geleerd kunnen worden door de AI tools. Het is duidelijk dat de ene vraag moeilijker is dan de andere: het is veel moeilijker een kenmerk met 10 mogelijke waarden helemaal correct te voorspellen dan een kenmerk met 2 of 3 waarden. We hebben hier geen poging gedaan om specifieke netwerk-architecturen voor bepaalde kenmerken op te zetten, maar gebruiken standaard configuraties. Dat, gevoegd bij het (voor AI) relatief kleine aantal voorbeelden, leidt tot succespercentages van 50-90%, afhankelijk van het kenmerk. Alhoewel veelbelovend, is dat voor praktische toepassingen nog steeds te laag. Iets dergelijks geldt voor het herkennen van kleuren: daarin wordt 85% van de hoofdkleuren in de beelden goed voorspeld, zowel door de AI methoden als door de klassiekere aanpak. Bij kleur lijkt het er overigens wel op dat dit dicht bij het maximum haalbare zit: in zekere zin zijn kleuren slecht gedefinieerd en is er vaak ruimte voor discussie, zeker bij erg lichte kleuren.
Analyseren van kleuren
Een voorbeeld van de klassieke kleuranalyse is te zien in de figuur hiernonder: links het originele beeld (met de grijze achtergrond verwijderd, en afgebeeld in zwart); in het midden de gevonden kleuren, afhankelijk van de afstand tot het midden van de bloem, en rechts de reconstructie gebruik makend van de (hier: 7) gedetecteerde kleuren. Hieruit kunnen we niet alleen de hoofdkleuren van de verschillende onderdelen van de bloem afleiden, maar ook de grootte van de bloem en verschillende bloem-onderdelen (in aantal pixels).
Om op het gebied van kleurherkenning nog vooruitgang te boeken is in 2023 onderzocht hoe een eenvoudige standaardisatie op grond van standaard kleurenkaarten kan worden gebruikt. In een set experimenten is daarbij aangetoond dat de effecten van niet-standaard belichting behoorlijk goed gecorrigeerd kunnen worden, waardoor deze methode veel makkelijker in de praktijk toe te passen is, en waardoor een verregaande standaardisatie van omstandigheden zoals belichting minder belangrijk is geworden.
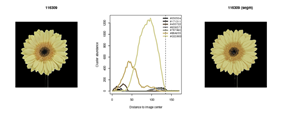
Afronding project
In de laatste fase van het project is een prototype ontwikkeld, dat voor een database van beelden en kenmerken de gebruiker in staat stelt bloemen op een eenvoudige manier te vergelijken, en ook te vergelijken met bijvoorbeeld handmatig ingestelde waarden. Van dit prototype, als open source software te downloaden van https://github.com/Biometris/modoma, is ook een demo-versie beschikbaar (via https://shiny.wur.nl/modoma), waarbij de data van de Floricode gerbera set gebruikt worden om de mogelijkheden van het prototype te illustreren. Overigens kan het prototype ook gebruikt worden voor andere objecten dan sierbloemen – het is zo geschreven dat ook gegevens van bijvoorbeeld groenten of andere planten op dezelfde wijze geanalyseerd kunnen worden. Behalve deze software heeft het project ook twee wetenschappelijke artikels opgeleverd, die op dit moment onder review zijn.
In de afsluitende vergadering, op 21 april 2023, is tenslotte voor alle deelnemers en de klankbordgroep een overzicht van de bereikte resultaten gegeven.